앞의 다른 Chapter에서 살펴본 gawk의 기본 사용법에 이번 장에서는 좀더 자세한 gawk의 사용법을 알아 보도록 하겠 습니다.
1. 변수 사용하기
어떤 프로그램이 던지 변수를 사용하여 데이터를 저장하고 다시 불러내서 사용하는것은 주용한 기능 중에 하나 입니다. awk는 아래 2가지 타입의 변수를 지원 합니다.
■ Built-in variables
■ User-defined variables
Built-in variables
앞의 chapter에서 보아 왔듯이 달러 '$' 기호와 뒤에 번호를 붙이면 기록된 데이터를 참조 할수가 있습니다.
데이터 필드들의 구분은 FS(Field separotr)에 의해서 구분이 됩니다. 기본적으로 FS는 Space로 설정이 되어 있고 아래표는 데이터필드에 어떤 구분자들이 있는지 표를 통해 보여 주고 있ㅅ습니다.
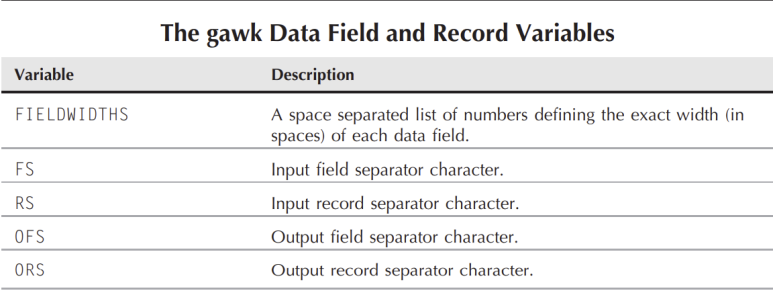
OFS는 사용하는 방법을 아래의 예제를 통해 살펴 보도록 하겠 습니다.
|
$ cat data1
data11,data12,data13,data14,data15
data21,data22,data23,data24,data25
data31,data32,data33,data34,data35
$ gawk ’BEGIN{FS=","} {print $1,$2,$3}’ data1 ==> ofs의 구분자를 컴마','로 구분 후 출력
data11 data12 data13
data21 data22 data23
data31 data32 data33 $
다음은 OFS를 변경하여 출력을 하도록 해 보겠습니다.
$ gawk ’BEGIN{FS=","; OFS="-"} {print $1,$2,$3}’ data1
data11-data12-data13
data21-data22-data23
data31-data32-data33
$ gawk ’BEGIN{FS=","; OFS="--"} {print $1,$2,$3}’ data1
data11--data12--data13
data21--data22--data23
data31--data32--data33
$ gawk ’BEGIN{FS=","; OFS="‹--›"} {print $1,$2,$3}’ data1
data11‹--›data12‹--›data13
data21‹--›data22‹--›data23
data31‹--›data32‹--›data33
$
이번에는 fieldwidth 변수를 활용하여 출력물의 길이를 조절해 보도록 하겠 습니다.
$ cat data1b
1005.3247596.37
115-2.349194.00
05810.1298100.1
$ gawk ’BEGIN{FIELDWIDTHS="3 5 2 5"}{print $1,$2,$3,$4}’ data1b ==> 3 5 2 5의 길이로
100 5.324 75 96.37 ==> 위에서 설정한 길이대로 출력됨을 볼수 있습니다.
15 -2.34 91 94.00 058
10.12 98 100.1
$
RS와 ORS를 사용하는 방법을 알아 보도록 합시다. 이래의 데이터를 살펴 보도록 하겠 습니다.
아래는 이름과 주소 그리고 전화번호로 구성된 3개의 라인에 데이터가 걸쳐 있는 구조 입니다.
만약 여기서 이름과 번화번호만 출력을 하고 싶을때 어떻게 할까요? 기본 FS와 RS를 사용하면 gawk에디터는 가각의 라인을 분리된 데이터 레코드로 인식을 하고 각 단어 사이의 Space를 FS로 인식을 하게 됩니다. 여기서 원하는 결과를 만들기 위해 RS와 FS를 변경하여 원하는 결과를 아래의 예제처럼 실행 시켜 보도록 하겠습니다.
Riley Mullen
123 Main Street Chicago, IL 60601
(312)555-1234
Frank Williams
456 Oak Street Indianapolis, IN 46201
(317)555-9876
Haley Snell
4231 Elm Street
Detroit, MI 48201
(313)555-4938
$ gawk ’BEGIN{FS="\n"; RS=""} {print $1,$4}’ data2 fs를 뉴라인캐릭터, RS를 공백으로 설정
RS를 공백으로 설정한 이유는 위의 데이터사이에 구분자가 공백 라인이기 때문 입니다.
Riley Mullen (312)555-1234
Frank Williams (317)555-9876
Haley Snell (313)555-4938 $
|
위에서 살펴본 변수를 이외에도 gawk는 아래와 같은 Built-In 변수를 제공 합니다.
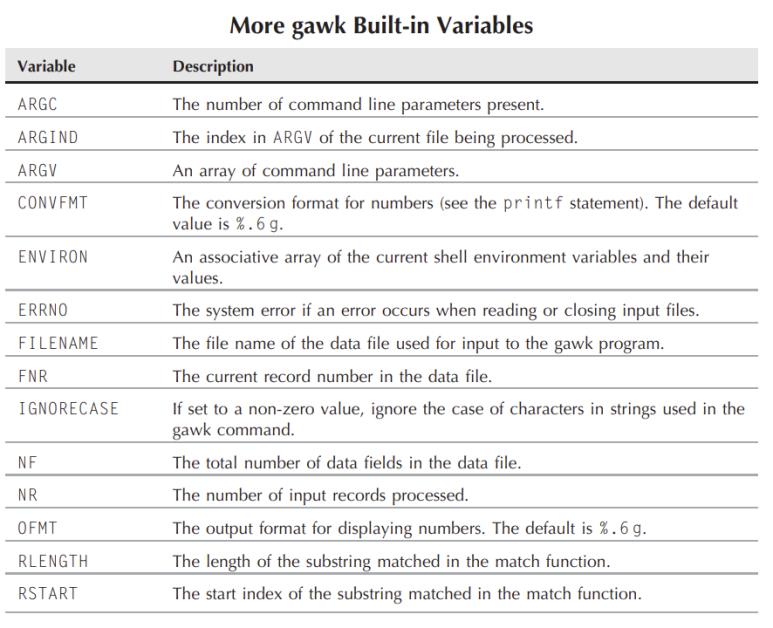
아래의 예제를 살펴 보도록 하겠 습니다.
|
$ gawk ’BEGIN{print ARGC,ARGV[1]}’ data1
==>ARGV는 명령어 라인에 있는 파라메터 갯수를 표시
==> ARGV는 명령어 라인에 있는 파라메터들의 배열이고 0부터 시작,
출력 결과
2 data1 ==> 명령어 라인에 파라메터는 2개 이고 두번째 파라메터는 data1 입니다.
|
ENVIRON 변수는 쉘 환경 변수를 조회 하기 위해 연관된 배열을 사용하게 되는데 이 연관된 배열의 인덱스 값은 숫자가 아니라 텍스트를 사용하게 됩니다. 아래 예를 살펴 보겠 습니다.
|
$ gawk ’
› BEGIN{
› print ENVIRON["HOME"] 환경 변수 중 HOME의 값을 출력
› print ENVIRON["PATH"] 환경 변수 중 PATH 의 값을 출력
› }’
/home/rich
/usr/local/bin:/bin:/usr/bin:/usr/X11R6/bin
$
NF 변수는 데이터 필드의 마지막 위치를 알수 없을때 사용을 하기 유용 합니다.
아래 예제는 /etc/passwd에서 데이터의 첫부분과 마지막 부분의 데이터를 출력 하는 예제 입니다.
$ gawk ’BEGIN{FS=":"; OFS=":"} {print $1,$NF}’ /etc/passwd
rich:/bin/bash ==> 데이터의 첫번째 rich와 마지막 /bin/bash를 출력해 줍니다.
testy:/bin/csh
mark:/bin/bash
dan:/bin/bash
FNR의 사용 예제를 살펴 보겠습니다. FNR은 현재 데이터 파일에서 처리도니 레코드의 숫자를 표시 해 줍니다.
$ gawk ’BEGIN{FS=","}{print $1,"FNR="FNR}’ data1 data1
data11 FNR=1
data21 FNR=2
data31 FNR=3
data11 FNR=1
data21 FNR=2
data31 FNR=3
$
NR은 처리되는 레코드의 총 숫자를 표시해 줍니다. 아래 예제를 살펴 보겠 습니다.
$ gawk ’
› BEGIN {FS=","}
› {print $1,"FNR="FNR,"NR="NR}
› END{print "There were",NR,"records processed"}’ data1 data1
data11 FNR=1 NR=1
data21 FNR=2 NR=2
data31 FNR=3 NR=3
data11 FNR=1 NR=4
data21 FNR=2 NR=5
data31 FNR=3 NR=6
There were 6 records processed
$
|
User-defined variables
gawk 에디터에서 사용할 수 있는 변수 이름은 숫자나 문자 언더 스코어 등을 살수 있습니다. 다만 변수명이 숫자로 시작을 할 수는 없습니다. 그리고 gawk 에디터는 대소문자를 구분을 합니다.
스크립트에서 변수 할당 하기
예제를 통해 살펴 보도록 합니다.
|
$ gawk ’
› BEGIN{
› testing="This is a test"
› print testing
› }’
This is a test
$
$ gawk ’
› BEGIN{
› testing="This is a test"
› print testing
› testing=45 ==> 변수에 숫자도 저장을 할 수 있습니다.
› print testing
› }’
This is a test
45
$
수식도 gawk에서 사용이 가능 합니다.ㅣ
$ gawk ’BEGIN{x=4; x= x * 2 + 3; print x}’
11
$
다른 예제를 살펴 보도록 하겠 습니다.
$ cat script2
BEGIN{print "The starting value is",n; FS=","}
{print $n}
$ gawk -f script2 n=3 data1
The starting value is ==> begin 섹터에서는 변수가 유효가 하지 않아 n값이 출력이 되지 않음
data13
data23
data33
$
n변수를 출력 하기 위해서는 begin 섹터 이전에 변수를 전달을 해야 하는데, 이를 가능하게 하는게 -v 옵션 입니다. 아래 예제를 살펴 봅시다.
$ gawk -v n=3 -f script2 data1
The starting value is 3 ==> 원하는 결과값을 얻을 수가 있습니다.
data13
data23
data33
$
|
2. 배열 사용하기
많은 프로그램들이 하나의 변수에 여러개의 데이터를 저장하기 위해 배열을 제공을 합니다.
var는 배열의 이름 이고 index는 배열의 몇번째에 데이터를 저장할지를 설정을 하면 선언 방법은 아래와 같습니다.
var[index] = element
예제를 통해 살펴 보도록 하겠 습니다.
|
capital["Illinois"] = "Springfield"
capital["Indiana"] = "Indianapolis"
capital["Ohio"] = "Columbus"
위는 배열에 데이터를 입력을 하는 예제 입니다. 이 입력된 데이터를 스크립트를 이용해 출력을 해 보도록 하겠습니다.
$ gawk ’BEGIN{
› capital["Illinois"] = "Springfield"
› print capital["Illinois"]
› }’
Springfield
$
다음은 숫자롤 인덱스로 사용하는 예제 입니다.
$ gawk ’BEGIN{
› var[1] = 34
› var[2] = 3
› total = var[1] + var[2]
› print total
› }’
37
$
|
연관 배열 변수의 반복 호출
연관배열에 저장된 데이터를 모두 출력을 하는건 조금 까다롭 습니다. 그 이유는 인덱스가 문자일 경우에는 모든 인덱스 값을 알기가 힘들기 때문 입니다. 그럼 이럴때에는 어떻게 해야 될까요. 아래의 형식을 사용하여 반복 호출을 할 수 있습니다.
[구문]
for (var in array)
{
statements
}
그럼 실제 사용하는 예제를 살펴 봅시다.
|
$ gawk ’BEGIN{
› var["a"] = 1
› var["g"] = 2
› var["m"] = 3
› var["u"] = 4
› for (test in var) ==> var배열의 인덱스를 test라는 변수에 저장을 합니다.
› {
› print "Index:",test," - Value:",var[test] ==> 인덱스 값과 그 인덱스에 저장된 데이터를 출력 합니다.
› }
› }’
Index: u - Value: 4
Index: m - Value: 3
Index: a - Value: 1
Index: g - Value: 2
$
|
배열의 인덱스값 삭제 하기
연관 배열에서 배열의 인덱스는 삭제 하는 방법은 delete명령을 이용하는 것 입니다. 사용 방법은 아래와 같습니다.
delete array[index]
delete명령을 이용해 삭제를 한 경우에는 해당 index에 저장되어 있는 데이터도 같이 삭제가 됩니다.
아래 예제를 살펴 봅시다.
|
$ gawk ’BEGIN{
› var["a"] = 1
› var["g"] = 2
› for (test in var)
› {
› print "Index:",test," - Value:",var[test] ==> var변수의 모든 데이터를 출력을 합니다
› }
› delete var["g"] ==> var의 배열에 g인덱스를 삭제
› print "---" ==> 삭제 후 구분을 위해 '---' 출력
› for (test in var)
› print "Index:",test," - Value:",var[test] ==> g인덱스가 삭제된 배열 var를 출력
› }’
Index: a - Value: 1
Index: g - Value: 2
---
Index: a - Value: 1
$
|
3. 패턴 이용하기
gawk도 sed처럼 데이터 필터를 위해서 여러가지 타입의 패턴을 제공을 합니다. 어떤 패턴들이 제공이 되는지 살펴 보겠 습니다.
정규 표현식 : 앞선 Chapter에서 본대로 정규식 표현을 지원 합니다.
정규 표현식 사용 방법의 예제를 살펴 보겠습니다.
정규식 표현은 반드시 스트립트에서 왼쪽 중괄호 앞에 나와야 합니다.
|
$ gawk ’BEGIN{FS=","} /11/{print $1}’ data1 ==> data1파일에서 11에 match 되는 데어터 출력
data11
$
$ gawk ’BEGIN{FS=","} /,d/{print $1}’ data1
data11
|
연산자를 사용하여 매치 하기
정규 표현식과 연산자를 사용하여 데이터 필터링을 좀더 세분화 되게 할수가 있습니다. 연산자 매칭 방법은 물결 기호 '~'를 이용하여 사용을 할 수 있습니다.
아래의 예를 보면 $1은 데어터 레코드에서 첫번째 데이터 필드를 의미를 하고 그 데이터 필드가 data문자로 시작되는 데이터필드를 필터링 해줍니다.
$1 ~ /^data/
몇가지 예제를 통해 살펴 봅시다.
|
$ gawk ’BEGIN{FS=","} $2 ~ /^data2/{print $0}’ data1 ==> 2번째 데이터 필드가 data2로 시작되는 데이터 출력.
data21,data22,data23,data24,data25
$
$ gawk -F: ’$1 ~ /rich/{print $1,$NF}’ /etc/passwd
==> etc/passwd파일의 첫번째 데이터 필드가 rich로 시작되는 첫번떼 데이터와 마지막 데이터 출력
rich /bin/bash
$
$ gawk ’BEGIN{FS=","} $2 !~ /^data2/{print $1}’ data1
==> data1 파일에서 두번째 데이터 필드가 data2로 시작하지 않는 레코드의 첫번째 데어터 필드 출력
data11 data31
$
|
수학적 표현
데이터 필드에서 숫자를 이용해 데이터 필터링을 하는 방법에 대해서 살펴 보도록 하겠 습니다.
root user에 속하는 모든 사용자를 출력하는 경우를 살펴 봅시다. 우선 root 그룹은 0번이고 이를 이용해서
/etc/passwd에서 root그룹에 속하는 user들을 출력을 해 보도록 하겠 습니다.
|
$ gawk -F: ’$4 == 0{print $1}’ /etc/passwd => 4번째 데이터 필드의 값이 0인 데어터의 첫번째 필드 출력
root
sync
shutdown
halt
operator
$
|
gawk에서 사용가능한 산술비교는 다음과 같습니다.
■ x == y: x와 y는 같다
■ x ‹= y: x는 y보다 작거나 같다
■ x‹y: x는 y보다 작다
■ x ›= y x는 y보다 크거나 같다
■ x›y: x는 y보다 크다
산술식을 활용해 텍스트 매치의 예제를 살펴 보겠 습니다.
|
$ gawk -F, ’$1 == "data"{print $1}’ data1
$ ==> data1파일에 data와 매치 되는 필드가 없음
$ gawk -F, ’$1 == "data11"{print $1}’ data1
data11 ==> data11과 매치 되는 데이터 출력
$
|
4. 구조화된 명령어
쉘프로그램과 같이 gawk도 구조화된 명령어들을 지원을 합니다. 각 구문별로 살펴 보겠 습니다.
if구문
gwak 에디터는 if-then-else 구문을 지원을 합니다. 사용 구문은 아래와 같습니다 .
if (condition) ==> 조건절이 참이면 statement실행, 아니면 생략 합니다.
statement1
개별적인 예제를 살펴 보겠 습니다.
|
$ cat data4
10
5
13
50
34
$ gawk ’{if ($1 › 20) print $1}’ data4 ==> 20보다 큰 수만 출력 합니다.
50
34
$
$ gawk ’{
› if ($1 › 20) ==> 첫번째 데이터 필드가 20보다 크면
› {
› x = $1 * 2 ==>x에 입력된 수 * 2의 결과를 저장
› print x ==> x를 출력
› }
› }’ data4
100
68
$
아래는 if -else구문을 활용한 예제 입니다.
$ gawk ’{
› if ($1 › 20) ==> 첫번째 데이터 필드가 20보다 크면
› {
› x = $1 * 2 ==> 첫번째 데이터 값에 2를 곱한값을 x에 저장
› print x ==> x를 출력
› } else ==> 첫번째 데이터 필드가 20보다 작으면
› {
› x = $1 / 2 ==> 첫번째 데이터필드를 반으로 나누어서 x에 저장
› print x › }}’ data4 ==> x값을 출력
5
2.5
6.5
100
68
$
$ gawk ’{if ($1 › 20) print $1 * 2; else print $1 / 2}’ data4 ==> if와 els를 한라인에 표시
5
2.5
6.5
100
68
$
|
while 구문
반복적인 작업을 처리 하기 위해 gawk에섣 while구문을 지원을 합니다.
그 사용구문은 아래와 같습니다.
|
while (condition)
{
statements
}
$ cat data5
130 120 135
160 113 140
145 170 215
$ gawk ’{
› total = 0
›i=1
› while (i ‹ 4) ==> i값이 4보다 작으면 반복
› {
› total += $i ==> total 변수에 i번째 데이터 필드를 저장
› i++ ==> i값을 증가
› }
› avg = total / 3 ==> avg변수에 평균값 저장
› print "Average:",avg ==> 평군값 출력
› }’ data5
Average: 128.333
Average: 137.667
Average: 176.667
$
while구문 역시 break와 continue명령을 지원을 합니다. 아래의 예제를 살펴 봅시다.
$ gawk ’{
› total = 0
›i=1
› while (i ‹ 4) ==> i값이 4보다 작은동안에 반복
› {
› total += $i
› if (i == 2) ==> i값이 2이면 while문 탈출
› break
› i++
› }
› avg = total / 2
› print "The average of the first two data elements is:",avg
› }’ data5
The average of the first two data elements is: 125
The average of the first two data elements is: 136.5
The average of the first two data elements is: 157.5
$
|
do-while 구문
이 구문은 while구문과 비슷하지만 while구문의 반복을 하기 전에 먼저 do문을 실행을 시킵니다.
do
{
statements
}
while (condition)
예제를 통해 살펴 봅시다.
|
total값이 150보다 큰 경우에만 출력 하기.
$ gawk ’{
› total = 0
›i=1
› do
› {
› total += $i ==> total변수에 i번째 데이터값을 입력을 합니다.
› i++
› } while (total ‹ 150) ==> total값을 확인을 하고 150보다 작으면 do를 반복
› print total }’ data5
250
160
315
$
|
for 구문
다른 모든 프로그램과 마찬 가지로 gawk도 for 구문을 지원을 하며, 그 구문은 아래와 같습니다.
for( variable assignment; condition; iteration process)
|
위에서 평균값을 구한 스크립트를 이번에는 for구문을 이용해 실행해 보겠 습니다.
$ gawk ’{
› total = 0
› for (i = 1; i ‹ 4; i++)
› {
› total += $i
› }
› avg = total / 3
› print "Average:",avg
› }’ data5
Average: 128.333
Average: 137.667
Average: 176.667
$
|
5. Formatted Printing
일반 print 명령으로는 사용자가 원하는 출력의 형식을 얻기가 힘듭니다. 어떤 형식화된 출력이 필요할때 printf명령을 사용을 할 수 있습니다.
사용 구문은 아래와 같습니다.
printf "format string", var1, var2...
format string 은 출력되는 형식의 키 값으로 동작 합니다. 이 포맷 스트링은 텍스트와 format specifiers를 이용하여 출력되는 데이터의 형식을 정하게 되는데, format specifier는 어떤 타입의 변수가 표시될지를 표시하는 특수 코드라고 보면 될것 같습니다. 이 format specifier의 사용 형식은 아래와 같습니다.
%[modifier]control-letter
contorl-letter는 어떤 타입의 데이터 값이 표시될지를 나타내는 문자 입니다. modifier는 추가적은 포맷 기능을 사용할때 이용을 합니다. 아래는 사용가능한 control-letter를 나타낸 표 입니다.
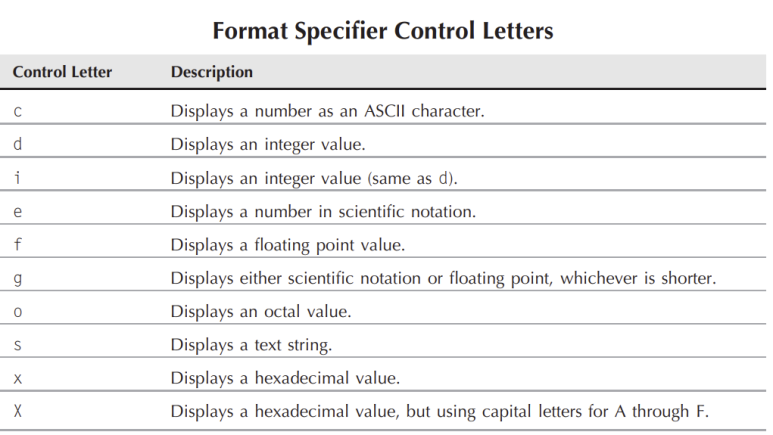
출력 데이터를 스크링으로 표시할때는 %s로 정수형으로 나타내고 싶을때는 %i또는 %d를 사용해야 합니다.
|
과학적 표기법을 이용한 큰수 표현 하기.
$ gawk ’BEGIN{
› x = 10 * 100
› printf "The answer is: %e\n", x
› }’
The answer is: 1.000000e+03
$
|
추가로 사용 가능한 modifier
■ width: 출력 필드의 최소 너비를 지정하는 숫자 값입니다. 만약 출력이 더 짧으면 printf에 대한 오른쪽 맞춤을 사용하여 공백으로 공백을 채웁니다. 텍스트. 출력이 지정된 너비보다 길면 너비 값을 덮어 씌웁니다.
■ prec: 부동 소수점 숫자의 소수점 오른쪽 자릿수 또는 텍스트 문자열에 표시되는 최대 문자 수를 지정하는 숫자 값입니다.
■ − (minus sign): 빼기 기호는 형식이 지정된 공간에 데이터를 배치할 때 오른쪽 맞춤 대신 왼쪽 맞춤을 사용해야 함을 나타냅니다.
|
printf 를 사용하여 몇가지 예제를 살펴 보도록 하겠습니다.
앞서 살펴본 스크립트중 이름과 전화번호를 표시하는 스크립트를 print와 printf를 비교해 보겠 습니다.
print 명령을 사용한 스크립트
$ gawk ’BEGIN{FS="\n"; RS=""} {print $1,$4}’ data2
Riley Mullen (312)555-1234
Frank Williams (317)555-9876
Haley Snell (313)555-4938
$
printf 명령을 사용한 스크립트
$ gawk ’BEGIN{FS="\n"; RS=""} {printf "%s %s\n", $1, $4}’ data 2
Riley Mullen (312)555-1234
Frank Williams (317)555-9876
Haley Snell (313)555-4938
$
%s\n갑시 추가로 들어간 이유는 뉴라인케릭터를 추가해 주어야 합니다. 이 값이 없으면 동일한 라인에 출력이 다른 데이터들이 같이 출력이 되게 됩니다.
%s\n 대신에 BEGIN과 END를 이용할 수도 있습니다.
$ gawk ’BEGIN{FS=","} {printf "%s ", $1} END{printf "\n"}’ data1
data11 data21 data31
$
사림의 이름이 출력되는 첫번째 데이터의 공간을 16칸으로 설정을 하는 예제 입니다.
$ gawk ’BEGIN{FS="\n"; RS=""} {printf "%16s %s\n", $1, $4}’ data2
Riley Mullen (312)555-1234
Frank Williams (317)555-9876
Haley Snell (313)555-4938
$
printf명령은 기본적으로 오른쪽 정렬이 선택이 됩니다. 이를 왼쪽 정렬로 바꾸고 싶으면 마이너스'-'을 아래와 같이 사용을 하면 됩니다.
$ gawk ’BEGIN{FS="\n"; RS=""} {printf "%-16s %s\n", $1, $4}’ data2
Riley Mullen (312)555-1234
Frank Williams (317)555-9876
Haley Snell (313)555-4938
$
아래는 부동현 소수점을 총 5개의 길이와 1개의 소수점만 표시하게 하는 예제 입니다.
$ gawk ’{
› total = 0
› for (i = 1; i ‹ 4; i++)
› {
› total += $i
› }
› avg = total / 3
› printf "Average: %5.1f\n",avg › }’ data5
Average: 128.3 ==> 출력 총 자릿수는 소수점을 포함한 5자리에 소수점 이하 한자리 표시
Average: 137.7
Average: 176.7 $
|
6. Built-In Function 사용하기
gwak에서는 산술연산이나, 문자열, 시간함수를 위한 Built In 함수를 사용할 수 있습니다.
gwak는 아래표와 같은 산술적 함수를 지원 합니다.
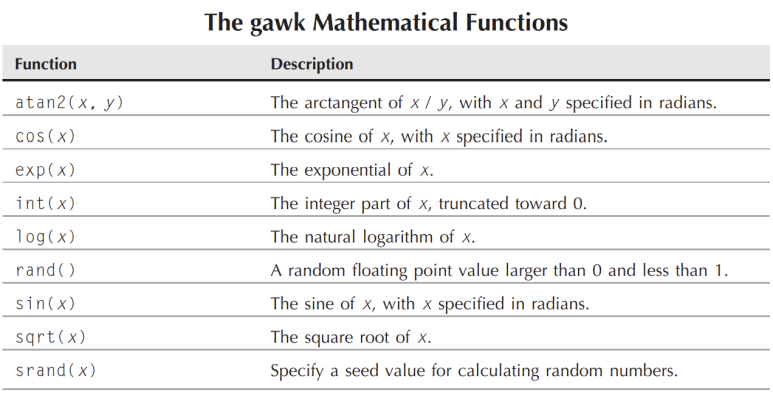
산술적인 함수 이외에도 아래와 같은 비트 기반의 연산도 지원을 합니다.
■ and(v1, v2): v1과 v2의 값을 and 연산
■ compl(val): 비트 기반의 보수 연산
■ lshift(val, count): val의 값을 count만큼 왼쪽으로 이동
■ or(v1, v2): v1, v2의 or 연산
■ rshift(val, count):val의 값을 count만큼 오른족으로 이동
■ xor(v1, v2): 비트 기반의 v1, v2를 XOR 연산
문자열 함수 사용하기
gwak에서 사용할수 있는 문자열 함수는 아래의 표와 같습니다.

몇개의 예제를 살펴 봅시다.
|
소문자를 대문자로 바꾸고 자릿수를 표시해 주는 예제 입니다 .
$ gawk ’BEGIN{x = "testing"; print toupper(x); print length(x) }’
TESTING
7
$
asort: 데이터 값에 따라 정렬, asoti: index값에 따라 정렬
$ gawk ’BEGIN{
› var["a"] = 1
› var["g"] = 2
› var["m"] = 3
› var["u"] = 4
› asort(var, test) ==> var의 배열을 정렬하여 test에 저장
› for (i in test)
› print "Index:",i," - value:",test[i] ==> test의 index값은 숫자로 변경이 되었 습니다.
› }’
Index: 4 - value: 4
Index: 1 - value: 1
Index: 2 - value: 2
Index: 3 - value: 3
$
다음은 split 함수를 사용하는 예제를 살펴 보겠 습니다.
$ gawk ’BEGIN{ FS=","}{
› split($0, var) ==> $0의 입력값을 var배열의 각 데이터 필드에 삽입.
› print var[1], var[5]
› }’ data1
data11 data15
data21 data25
data31 data35
$
|
시간 함수 사용하기.
gwak에서도 시간함수를 지원을 합니다. 그 중 사용 가능한 함수들은 아래표와 같습니다.

7. 사용자 정의 함수 사용하기
gawk에서는 사용자가 함수를 정의하여 스크립트에서 사용을 할 수 있습니다.
함수 정의 하기
사용자 함수정의를 사용하기 위해서는 아래와 같은 구문을 사용을 하면 됩니다.
function name([variables])
{
statements
}
사용자 정의 함수를 하나 만들어 보도록 합시다.
|
$ gawk ’
› function myprint() ===> myprint라는 함수를 정의
› {
› printf "%-16s - %s\n", $1, $4
==> 첫번때 데이터 필드가 16자리의 문자열로 설정, 뉴라인 케릭터가 나오면 줄바꿈을하는
첫번째와 4번째 데이터 필드를 출력 하는 명령 입니다.
› }
› BEGIN{FS="\n"; RS=""} ==> 대이터 필그 구분은 뉴라인 캐릭터, 레코드 분류는 공백
› {
› myprint()
› }’ data2
Riley Mullen - (312)555-1234
Frank Williams - (317)555-9876
Haley Snell - (313)555-4938 $
|
함수 라이브러리 생성하기
함수를 만들고 다시 쓰기 위해서 또 만들고 하는일은 여간 번거로은 작업이 아닙니다. 그래서 만들어 놓은 함수를 라이브러리에 저장하여 나중에 사용할때 라이브러리를 호출 하여 사용을 할 수 있습니다.
첫번째로 해야 될것은 gwak의 모든 함수가 포함된 파일을 만드는 것 입니다 .
아래 예를 통해 살펴 보겠 습니다.
|
$ cat funclib ==> 라이브러리 파일 안에 만들어 놓은 함수를 확인해 봅시다.
function myprint()
{
printf "%-16s - %s\n", $1, $4
}
function myrand(limit)
{
return int(limit * rand())
}
function printthird() {
print $3
}
사용핧 스크립트 파일의 내용을 살펴 봅시다.
$ cat script4
BEGIN{ FS="\n"; RS=""}
{
myprint()
}
다음은 위의 스크립트와 라이브러리 파일을 이용하여 실행을 시켜 보도록 하겠 습니다.
-f 옵션을 사용해서 라이브러리 파일을 지정을 해 줍니다. 그리고 -f를 이용해 스크립트 파일을 지정 합니다.
$ gawk -f funclib -f script4 data2
Riley Mullen - (312)555-1234
Frank Williams - (317)555-9876
Haley Snell - (313)555-4938
$
|
그럼 오늘은 여기 까지.......
'쉘스크립트' 카테고리의 다른 글
| Web 사용하기 (1) | 2022.07.06 |
|---|---|
| Database 이용하기 (0) | 2022.07.06 |
| 진화된 sed (1) | 2022.07.06 |
| 정규 표현식 (2) | 2022.07.06 |
| sed와 gawk의소개 (3) | 2022.07.06 |