If we rearrange the Pod, Service, Deployment, and replacaset that we looked at earlier, the smallest unit for a service in Kubernetes is a Pod. A container is placed in this Pod, and an application is run in the container to process service requests. Communication between Pods communicates through an object called Service, and you can think of a Deployment object as an object that manages deployed Pods in a specific state.
The following problems exist when a new pod is created after a failure after the pod is deployed or when a new pod is created. The first problem is that when a pod is newly created, Kubernetes sends traffic as soon as the pod state becomes the Run state. Usually, when only the container is running, the Pod is in the Run state, and it does not check whether the application is running properly. In this case, even if the Pod is in the Run state, it takes a certain amount of time to start the application. If a request message is sent to the Pod before the application is even started, a service processing failure is issued and a problem occurs. Second, like deadlock, the container operates normally, but even if the application is deadlocked, the service object sends a service request to the pod because the pod is in the run state. will do.
To prevent such a case, Container Prob is used. There are two types of probes as follows. Readness Prob: When the Pod is started, the Readness Prob checks whether the application is ready to process the service, and when it is ready, it informs Kubernetes that it is ready. As shown in the figure below, when the application loading is 100% complete, it will notify you that the service is ready for processing.
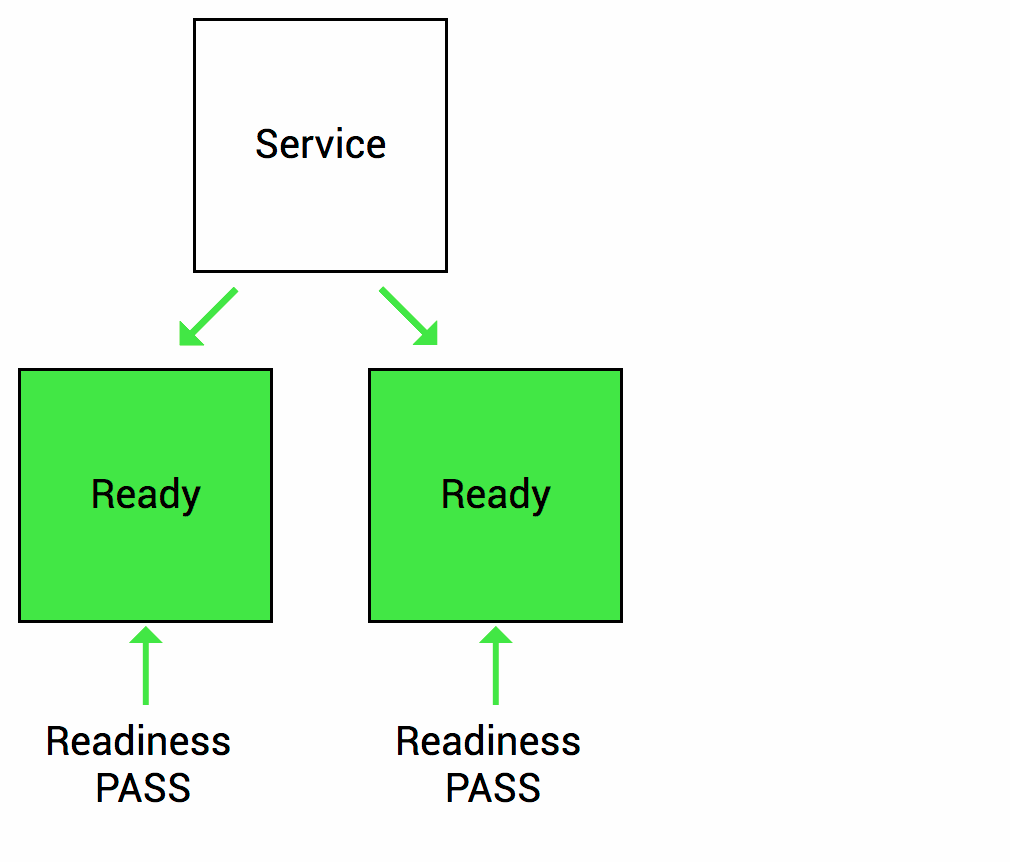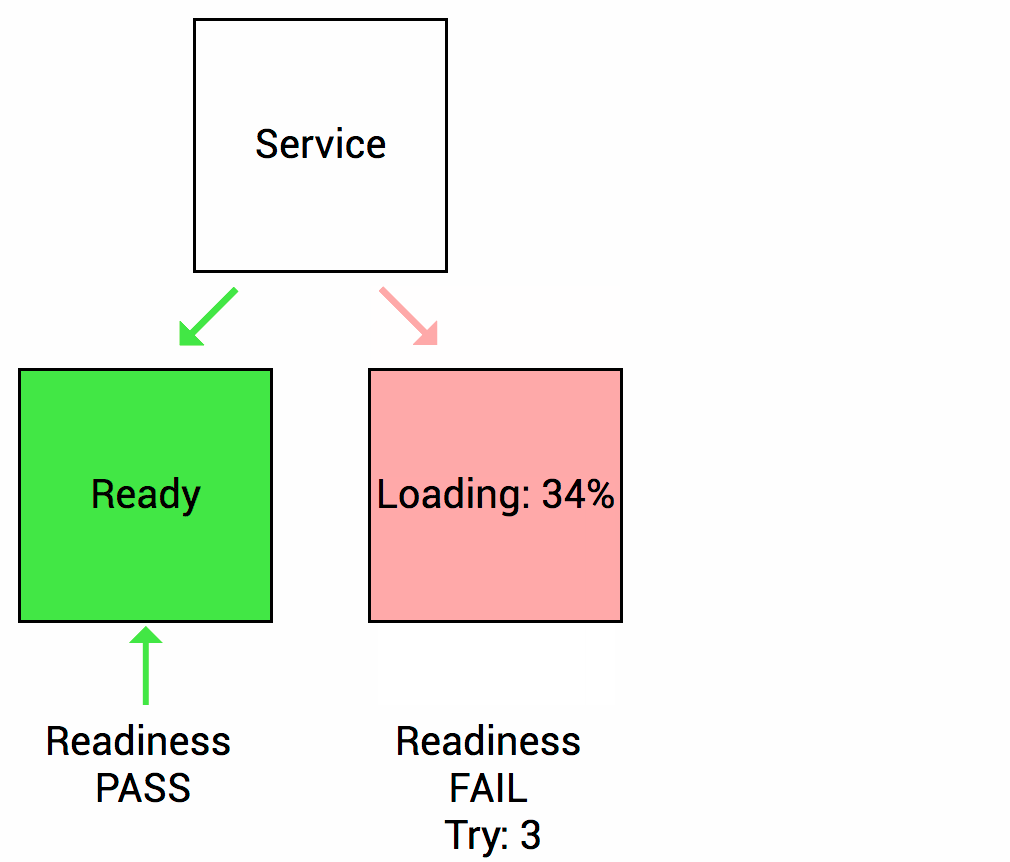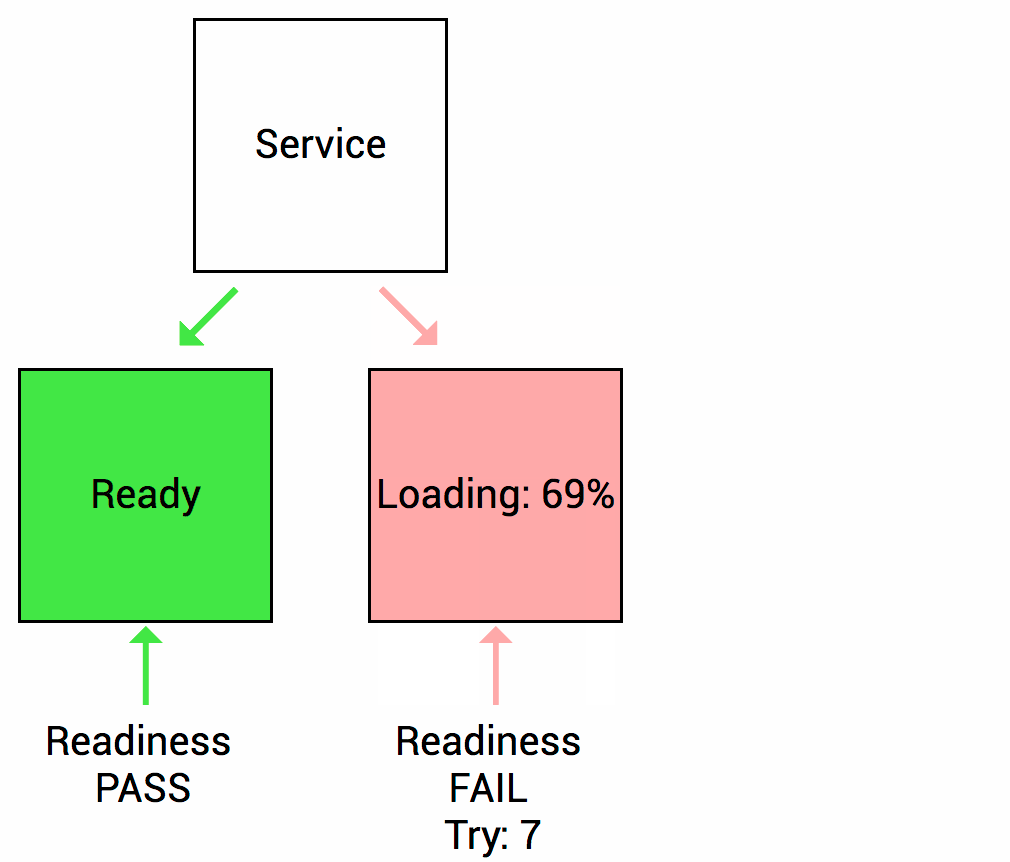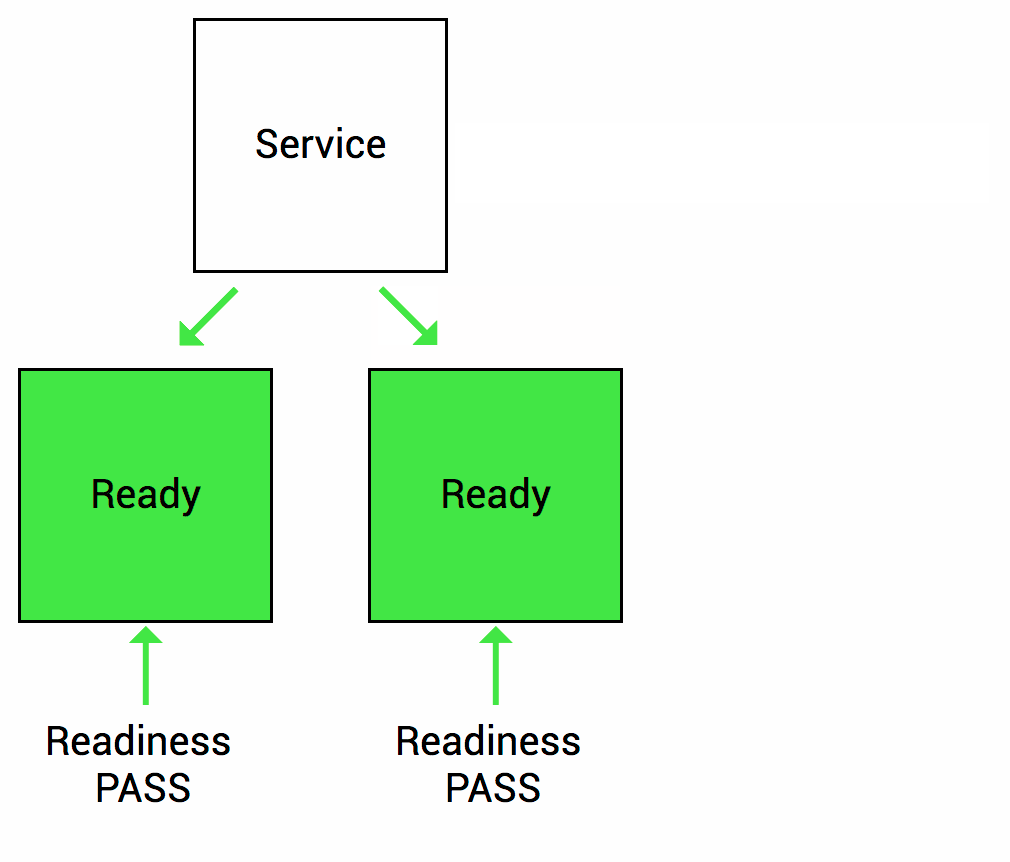
The second is the Liveness Prob. This Liveness checks whether the application is working properly in the middle of service processing after the Pod is created and ready in the Readness Prob, and notifies Kubernetes if the application fails so that the service request is not sent to the Pod. It is a Prob that does it.

The above two probes judge fail and ready through the health check of the application. There are three types of health check methods as follows.
The HTTP probe is the most commonly used type of liveness probe. Sends the traffic set to the probe to the HTTP server of the application and receives a response code of 200 to 400, it is normal, if it receives a response code other than that, it is marked as abnormal... Then the Prob defines the following parameters when deploying the Pod yaml so it can be implemented.
|
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-http
spec:
containers:
- name: liveness
image: k8s.gcr.io/liveness
args:
- /server
livenessProbe:
httpGet: ==>using httpGet method to check healty health check
path: /healthz ==> checking path
port: 8080 ==> using port number
httpHeaders:
- name: X-Custom-Header
value: Awesome
initialDelaySeconds: 3 ==>after 3 second to start checking Pod
periodSeconds: 3 ==> check in every 3second from initial check
|
Command probe is a probe type that checks whether the result of executing the command in the container is normal. If the command execution result code returns 0, it is marked as normal, otherwise it is marked as abnormal. The command probe type can be useful if your application cannot run an HTTP server. So let's take a look at the sample yaml.
|
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-exec
spec:
containers:
- name: liveness
image: k8s.gcr.io/busybox
args: ==> excuted command after run a Pod
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600
livenessProbe:
exec: ==> define periodically checked command
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5 ==> first check after 5 second from run a pod
periodSeconds: 5 ==> check in every 3second from initial check
|
In the example above, the command (cat, /tmp/health) under the exec parameter is checked every 5 seconds (periodSeconds), and if a fail occurs, the container is restarted and the command under the args parameter is executed after restarting.
The TCP probe type is marked as normal if Kubernetes attempts a TCP connection to the specified port and the connection succeeds, and abnormal if it cannot connect. TCP probe is useful when HTTP probe or command probe cannot be used, and typical types are gRPC or FTP service. So let's take a look at the sample yaml file.
|
apiVersion: v1
kind: Pod
metadata:
name: goproxy
labels:
app: goproxy
spec:
containers:
- name: goproxy
image: k8s.gcr.io/goproxy:0.1
ports:
- containerPort: 8080
readinessProbe: ==>define readness prob
tcpSocket:
port: 8080
initialDelaySeconds: 5 ==>initial check after 5second from run a pod
periodSeconds: 10 ==> check in every 10 second from initial check
livenessProbe: ==> define Liveness prob
tcpSocket: ==> use TCP socker
port: 8080 ==> define connection port
initialDelaySeconds: 15 ==> check after 15 second from a run pad
periodSeconds: 20 ==> check in every 20 second from initial check
|
그럼 이제 Prob를 정의를 할때 사용가능한 파라메터들을 살펴 보겠습니다.
- initialDelaySeconds: The amount of time to delay before the first probe is performed after the pod is created and the container is started.
- periodSeconds: Set the probe execution period. Default 10 seconds. Minimum value 1.
- timeoutSeconds: Set the timeout time to wait for probe execution response. Default 1 second. Minimum value 1. successThreshold: A field that sets how many times the probe must succeed before it is marked as successful. Default 1. Minimum value 1.
- failureThreshold: Set at least how many times a probe must fail to be marked as failed. When a Pod is started, if a Pobe fails, Kubernetes will try again as many times as set in failureThreshold. However, if it fails as many as the number of failureThreshold, it is marked as a failure, and the probe is abandoned without retrying. Defaults 3. Minimum value 1.
HTTP probes can additionally set the following fields.
- host: Host Name to connect to, default is pod IP.
- scheme: HTTP or HTTPS. Defaults to HTTP.
- path: The path to access the HTTP server.
- httpHeaders: Custom header settings.
- port: The port to access the container.
2. Resource limit
Now let's look at resource allocation. There is a minimum resource required for any application. For example, CPU is more than anything. How much more MEM. How many disks are there? If the application is assigned to a Pod that does not meet these conditions, it will not work. You can define the necessary resources for this.
How to implement it, you can define the minimum required specification by defining the resource parameter part in the Pod yaml. So let's take a look at the yaml file.
|
apiVersion: v1
kind: Pod
metadata:
name: frontend
spec:
containers:
- name: wp
image: wordpress
resources: ==>define resource
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
|
The resource parameter defines the minimum specification required when creating a Pod. If a particular cluster uses a lot of resources in multiple clusters in operation, it will affect other clusters. To avoid this, we use ResourceQuotas. resourcequota limits the resources available in a specific namespace. Take a look at the sample resource quota below.
|
apiVersion: v1
kind: List
items:
- apiVersion: v1
kind: ResourceQuota
metadata:
name: pods-high ==>define high level of resource
spec:
hard:
cpu: "1000"
memory: 200Gi
pods: "10"
scopeSelector:
matchExpressions:
- operator : In
scopeName: PriorityClass
values: ["high"]
- apiVersion: v1
kind: ResourceQuota
metadata:
name: pods-medium ==> define mid resource
spec:
hard:
cpu: "10"
memory: 20Gi
pods: "10"
scopeSelector:
matchExpressions:
- operator : In
scopeName: PriorityClass
values: ["medium"]
- apiVersion: v1
kind: ResourceQuota
metadata:
name: pods-low
spec:
hard:
cpu: "5"
memory: 10Gi
pods: "10"
scopeSelector:
matchExpressions:
- operator : In
scopeName: PriorityClass
values: ["low"]
|
As you can see in the red part above, we have created 3 grades of resource quota. Now let's take a look at the yaml that creates the Pods.
|
apiVersion: v1
kind: Pod
metadata:
name: high-priority
spec:
containers:
- name: high-priority
image: ubuntu
command: ["/bin/sh"]
args: ["-c", "while true; do echo hello; sleep 10;done"]
resources:
requests:
memory: "10Gi"
cpu: "500m"
limits:
memory: "10Gi"
cpu: "500m"
priorityClassName: high
|
The value of priorityClassName is defined as high. This means that resourcequata will use high among the three defined in scopeselector high, med, and low.
How to apply resourcequota to namespace is as below. 'kubectl apply -f resourcequotaname.yaml --namespaace=namespacename'
Next, we will learn about LimitRange. ResourceQuotas defines the resource limit for the entire namespace, while LimitRange is a resource limit for individual container units. That is, when users define resources for individual containers, it is a concept that limits the applicable scope. By doing this, users will not be able to create very small or very large containers.

If you look at resourcequota and limitrange as a picture, it is as above. This LimitRange operates with the limit value of all Pods in the cluster (namespace). Let's take a look at the sample limitrange yaml.
|
apiVersion: v1
kind: LimitRange ==>LimitRange define
metadata:
name: limit-range
namespace: phh-test-bo ==> define Namespce
spec:
limits:
- type: Pod
max: ==> maximum value of Pod
cpu: 1.2
memory: 2.5Gi
min: ==>minimum value of Pod
cpu: 0.5
memory: 1Gi
|
Pod's yaml file also has a parameter called request/limt, and the relationship between this value and LimitRange is as follows.
If request / limit of Resource is not specified in Pod yaml, set defaultRequest and max value of limit of LimitRange. If the Pod yaml request is specified, check if the Pod Resource Request value is a CPU/Memory value greater than or equal to the min value of LimitRange limit. If the pod yaml limit is specified, check if the Pod Resource Limit value is less than the max value of the LimitRange limit or less CPU/Memory value.
'Kubernetes' 카테고리의 다른 글
| [Cloud] 10. Using Kubernetes Configmap (24) | 2023.02.10 |
|---|---|
| [Cloud] 9. Kubernetes Daemonset deploy (42) | 2023.02.08 |
| [Cloud] 7. Deployment strategies (24) | 2023.02.05 |
| [Cloud] 6. Kubernetes Service deploy (24) | 2023.02.01 |
| [Cloud] 5. Kubernetes Deployment deploy (29) | 2023.01.30 |