
과제 1: 기존 실습 환경 검사
기존 환경의 구성을 검토합니다. AWS CloudFormation을 통해 다음 리소스가 프로비저닝되었습니다.
- Amazon Virtual Private Cloud(Amazon VPC)
- 2개의 가용 영역에 있는 퍼블릭 및 프라이빗 서브넷
- 퍼블릭 서브넷에 연결된 인터넷 게이트웨이(다이어그램에 표시되지 않음)
- 퍼블릭 서브넷 중 하나에 있는 NAT 게이트웨이
- 들어오는 애플리케이션 트래픽을 수신하고 전달하기 위해 2개의 퍼블릭 서브넷에 배포된 Application Load Balancer
- 프라이빗 서브넷 중 하나에 포함되어 있으며 기본적인 재고 추적 애플리케이션을 실행하는 EC2 인스턴스
- 재고 데이터를 저장하고 프라이빗 서브넷 중 하나에 있는 단일 DB 인스턴스가 포함된 Aurora DB 클러스터
다음 이미지는 최초 아키텍처를 보여 줍니다.

과제 1.1: 네트워크 인프라 검사
이 과제에서는 실습 환경의 네트워크 구성 세부 정보를 검토합니다.
- AWS Management Console 상단의 검색 창에서
VPC를 검색하여 선택합니다.
참고: Lab VPC는 실습 환경에서 이미 생성되었으며 이 실습 연습에서 사용되는 모든 애플리케이션 리소스가 해당 VPC에 포함되어 있습니다.
- 왼쪽 탐색 창에서 Your VPCs를 선택합니다.
기본 VPC와 함께 Lab VPC가 목록에 표시됩니다.
- 왼쪽 탐색 창에서 Subnets를 선택합니다.
Lab VPC에 속한 서브넷이 목록에 표시됩니다. Public Subnet 1의 열에 나열된 세부 정보를 검토합니다.
- VPC 열에서 이 서브넷이 연결된 VPC를 파악할 수 있습니다. 이 서브넷은 Lab VPC 안에 존재합니다.
- IPv4 Classless Inter-Domain Routing (CIDR) 열에서 10.0.0.0/24 값은 이 서브넷이 10.0.0.0과 10.0.0.255 사이의 IP 256개(이 중 5개는 예약되었으며 사용할 수 없습니다)를 포함한다는 뜻입니다.
- Availability Zone 열에서 이 서브넷이 있는 가용 영역을 파악할 수 있습니다. 이 서브넷은 “a”로 끝나는 가용 영역에 있습니다.
- 페이지 아래쪽에 세부 정보를 더 표시하려면 Public Subnet 1을 선택하면 페이지 하단에 추가 세부 정보가 표시됩니다.
참고: 구분선을 위아래로 끌어 하단 창을 확장할 수 있습니다. 아래쪽 창의 미리 설정된 크기를 선택하려는 경우 사각형 아이콘 3개 중 하나를 선택하면 됩니다.
- 페이지 하단에서 Route table 탭을 엽니다.
이 탭에는 이 서브넷의 라우팅에 대한 세부 정보가 표시됩니다.
- 첫 번째 항목은 VPC의 CIDR 범위(10.0.0.0/20) 내로 향하는 트래픽이 VPC(로컬) 내에서 라우팅되도록 지정합니다.
- 두 번째 항목은 인터넷(0.0.0.0/0)으로 향하는 트래픽이 인터넷 게이트웨이(igw-xxxx)로 라우팅되도록 지정합니다. 이 구성이 서브넷을 퍼블릭 서브넷으로 만듭니다.
- Network ACL 탭을 엽니다.
이 탭에는 서브넷과 연결된 네트워크 액세스 제어 목록(ACL)이 표시됩니다. 규칙은 현재 서브넷에서 모든 트래픽의 전송 및 수신을 허용합니다. 네트워크 ACL을 수정하거나 보안 그룹을 사용하여 트래픽을 추가로 제한할 수 있습니다.
- 왼쪽 탐색 창에서 Internet gateways를 선택합니다.
Lab IG라는 인터넷 게이트웨이가 이미 Lab VPC에 연결되어 있습니다.
- 왼쪽 탐색 창에서 Security groups를 선택합니다.
- Inventory-ALB 보안 그룹을 선택합니다.
이것은 Application Load Balancer에 들어오는 트래픽을 제어하는 데 사용되는 보안 그룹입니다.
- 페이지 하단에서 Inbound rules 탭을 엽니다.
이 보안 그룹은 어디서나 (0.0.0.0/0) 오는 인바운드 웹 트래픽(포트 80)을 허용합니다.
- Outbound rules 탭을 선택합니다.
기본적으로 보안 그룹은 모든 아웃바운드 트래픽을 허용합니다. 하지만 필요에 따라 이러한 규칙을 수정할 수 있습니다.
- Inventory-App 보안 그룹을 선택합니다. 이 보안 그룹만 선택해야 합니다.
이것은 AppServer EC2 인스턴스로 들어오는 트래픽을 제어하는 데 사용되는 보안 그룹입니다.
- 페이지 하단에서 Inbound rules 탭을 엽니다.
이 보안 그룹은 Application Load Balancer 보안 그룹 (Inventory-ALB) 에서 오는 인바운드 웹 트래픽(포트 80)만을 허용합니다.
- Outbound rules 탭을 선택합니다.
기본적으로 보안 그룹은 모든 아웃바운드 트래픽을 허용합니다. Application Load Balancer 보안 그룹의 아웃바운드 규칙과 마찬가지로 필요에 따라 이러한 규칙을 수정할 수 있습니다.
- Inventory-DB 보안 그룹을 선택합니다. 이 보안 그룹만 선택해야 합니다.
이것은 데이터베이스로 들어오는 트래픽을 제어하는 데 사용되는 보안 그룹입니다.
- 페이지 하단에서 Inbound rules 탭을 엽니다.
이 보안 그룹은 애플리케이션 서버 보안 그룹 (Inventory-App) 에서 오는 인바운드 MYSQL/Aurora 트래픽(포트 3306)만 허용합니다.
- Outbound rules 탭을 선택합니다.
기본적으로 보안 그룹은 모든 아웃바운드 트래픽을 허용합니다. 이전 보안 그룹의 아웃바운드 규칙과 마찬가지로 필요에 따라 이러한 규칙을 수정할 수 있습니다.
과제 1.2: EC2 인스턴스 검사
EC2 인스턴스는 이미 제공되어 있습니다. 이 인스턴스는 데이터베이스에서 재고를 추적하는 기본적인 하이퍼텍스트 프리프로세서(PHP) 애플리케이션을 실행합니다. 이 과제에서는 인스턴스 세부 정보를 검사합니다.
- 콘솔 상단의 검색 창에서 를 검색하여 선택합니다.
- EC2
- 왼쪽 탐색 창에서 Instances를 선택합니다.
- AppServer 인스턴스를 옆의 확인란을 선택하면 페이지 하단에 추가 세부 정보가 표시됩니다.
- 인스턴스 세부 정보를 검토한 후 Actions 메뉴 아래에서 Instance settings를 선택한 다음 Edit user data를 선택합니다.
- Edit user data 페이지에서 Copy user data를 선택합니다.
- 방금 복사한 사용자 데이터를 텍스트 편집기에 붙여 넣습니다. 이후 과제에서 사용하게 됩니다.
과제 1.3: 로드 밸런서 구성 검사
Application Load Balancer와 대상 그룹이 제공되어 있습니다. 이 과제에서는 그 구성을 검토합니다.
- 왼쪽 위의 메뉴 아이콘()을 선택하여 탐색 메뉴를 확장합니다.
- 왼쪽 탐색 창에서 Target Groups를 선택합니다.
- Inventory-App 대상 그룹 옆의 확인란을 선택하면 페이지 하단에 추가 세부 정보가 표시됩니다.
- 아래쪽 창에서 Targets 탭을 선택합니다.
Application Load Balancer는 들어오는 요청을 목록의 모든 대상에 전달합니다. 앞서 검사한 AppServer EC2 인스턴스는 이미 대상으로 등록되어 있습니다.
- 왼쪽 탐색 창에서 Load Balancers를 선택합니다.
- Inventory-LB 로드 밸런서 이름을 선택하여 추가 세부 정보를 표시합니다.
과제 1.4: 웹 브라우저에서 PHP 재고 애플리케이션 열기
재고 애플리케이션이 올바르게 작동 중인지 확인하려면 재고 애플리케이션 설정 페이지의 URL을 검색해야 합니다.
- 이 실습 지침 왼쪽의 InventoryAppSettingsPageURL을 클립보드에 복사합니다.
참고: URL은 http://Inventory-LB-xxxx.elb.amazonaws.com/settings.php와 비슷합니다.
- 새 웹 브라우저 탭을 열고 이전 단계에서 복사한 URL을 붙여 넣은 후에 Enter 키를 누릅니다.
재고 애플리케이션 설정 페이지가 표시됩니다. 데이터베이스 엔드포인트, 데이터베이스 이름, 로그인 세부 정보는 Aurora 데이터베이스의 값으로 이미 입력되어 있습니다.
- 재고 앱 설정 페이지의 모든 설정은 기본 구성 그대로 두십시오.
- Save를 선택합니다.
설정을 저장하면 재고 애플리케이션이 기본 페이지로 리디렉션되고, 다양한 항목의 재고가 표시됩니다. 재고에 항목을 추가하거나 기존 재고 항목의 세부 정보를 수정해도 됩니다. 이 애플리케이션과 상호 작용할 때 로드 밸런서는 로드 밸런서의 대상 그룹에서 이전에 본 AppServer로 요청을 전달합니다. AppServer는 Aurora 데이터베이스의 재고 변경 사항을 기록합니다. 웹 페이지 하단에는 인스턴스 ID와 인스턴스가 있는 가용 영역이 표시됩니다.
참고: 나머지 실습 과제를 수행하는 동안 이 재고 애플리케이션 웹 브라우저 탭을 열어 두십시오. 이후 과제에서 이 탭으로 다시 돌아옵니다.
축하합니다! 이제 실습 환경에서 생성된 모든 리소스 검사를 완료했으며 제공된 재고 애플리케이션에 액세스했습니다. 다음으로는 재고 애플리케이션을 고가용성으로 생성하기 위해 Amazon EC2 Auto Scaling과 함께 사용할 시작 템플릿을 생성합니다.
과제 2: 시작 템플릿 생성
참고: Auto Scaling 그룹을 생성하려면 먼저 Amazon Machine Image(AMI)의 ID 및 인스턴스 유형 등 EC2 인스턴스를 시작하는 데 필요한 파라미터가 포함된 시작 템플릿을 생성해야 합니다.
이 과제에서는 시작 템플릿을 생성합니다.
- 콘솔 상단의 검색 창에서 를 검색하여 선택합니다.
- EC2
- 왼쪽 탐색 창의 Instances 아래에서 Launch Templates를 선택합니다.
- Create launch template을 선택합니다.
- Launch template name and description 섹션에서 다음을 구성합니다.
- Launch template name:
Lab-template-NUMBER를 입력합니다.
참고: NUMBER는 다음 예와 같이 임의의 번호로 바꿉니다.
- Template version description:
version 1을 입력합니다.
참고: 사용하려면 템플릿 이름이 이미 있으면 다른 번호를 입력하여 이름을 다시 지정해 봅니다.
AMI를 선택해야 합니다 AMI는 인스턴스의 루트 볼륨과 운영 체제, 애플리케이션 및 관련 세부 정보를 정의하는 이미지입니다. 이 정보가 없으면 템플릿이 새 인스턴스를 시작할 수 없습니다.
다양한 운영 체제(OS)용 AMI를 사용할 수 있습니다. 이 실습에서는 Amazon Linux 2023 OS를 실행하는 인스턴스를 시작합니다.
- Application and OS Images (Amazon Machine Image) Info에서 Quick Start 탭을 선택합니다.
- Amazon Linux를 선택합니다.
- Amazon Machine Image에서 Amazon Linux 2023 AMI를 선택합니다.
- Instance type의 드롭다운 메뉴에서 t3.micro를 선택합니다.
인스턴스를 시작할 때 Instance type에 따라 인스턴스에 할당된 하드웨어가 결정됩니다. 각 인스턴스 유형은 서로 다른 컴퓨팅, 메모리, 스토리지 용량을 제공하며, 이 용량에 따라 서로 다른 인스턴스 패밀리로 분류됩니다.
- Security groups에서 Inventory-App을 선택합니다.
- Advanced details 섹션까지 아래로 스크롤합니다.
- Advanced details를 확장합니다.
- IAM instance profile의 경우 Inventory-App-Role을 선택합니다.
- Metadata version의 경우 V2 only (token required)를 선택합니다.
- User data 섹션에서 과제 1.2 도중 텍스트 편집기에 저장한 사용자 데이터를 붙여 넣습니다.
- Create launch template을 선택합니다.
- View launch templates을 선택합니다.
축하합니다! 시작 템플릿을 생성했습니다.
과제 3: Auto Scaling 그룹 생성
이 과제에서는 프라이빗 서브넷에 EC2 인스턴스를 배포하는 Auto Scaling 그룹을 생성합니다. 프라이빗 서브넷의 인스턴스는 인터넷에서 액세스할 수 없기 때문에 애플리케이션을 배포할 때는 이것이 보안 모범 사례입니다. 대신 사용자가 Application Load Balancer에 요청을 보내면 다음 다이어그램과 같이 해당 요청이 프라이빗 서브넷에 있는 EC2 인스턴스에 전달됩니다.
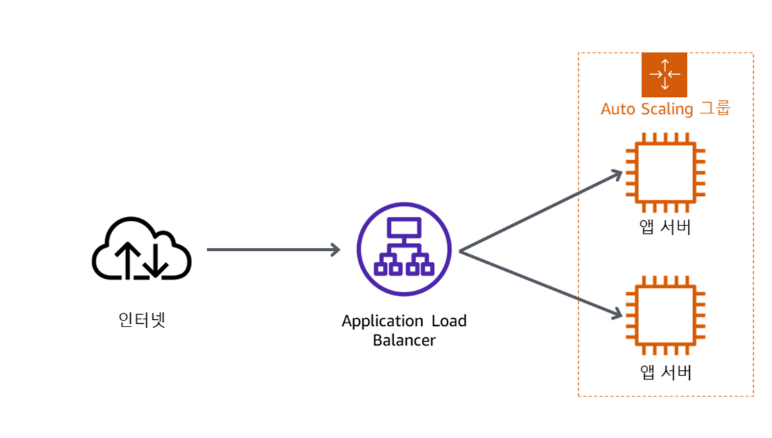
추가 정보: Amazon EC2 Auto Scaling은 사용자가 정의한 정책, 일정, 상태 확인 결과에 따라 자동으로 EC2 인스턴스를 자동으로 시작 또는 종료하도록 설계된 서비스입니다. 또한 여러 가용 영역에 인스턴스를 자동으로 분산하여 고가용성 애플리케이션을 생성할 수 있습니다. 자세한 내용은, 다음을 참조하십시오. Amazon EC2 Auto Scaling이란 무엇입니까?
- 왼쪽 탐색 창의 Auto Scaling 아래에서 Auto Scaling Groups를 클릭합니다.
- Create Auto Scaling group 버튼을 선택합니다.
- Auto Scaling group name:
Inventory-ASG를 입력합니다.
- Launch template: 드롭다운 메뉴에서, 이전 단계에서 생성한 시작 템플릿을 선택합니다.
- Next를 선택합니다.
Choose instance launch options 페이지가 표시됩니다.
- Network 섹션에서 다음을 구성합니다.
- VPC: 드롭다운 메뉴에서 Lab VPC를 선택합니다.
- Subnets: 드롭다운 메뉴에서 Private Subnet 1과 Private Subnet 2를 선택합니다.
- Next를 선택합니다.
- Configure advanced options - optional 페이지에서 다음을 구성합니다.
- Attach to an existing load balancer를 선택합니다.
- Choose from your load balancer target groups를 선택합니다.
- Existing load balancer target groups의 드롭다운 메뉴에서 Inventory-App | HTTP를 선택합니다.
그러면 앞에서 검사한 Inventory-App 대상 그룹의 일부로 새 EC2 인스턴스를 등록하라고 Auto Scaling 그룹에 지시합니다. 로드 밸런서가 이 대상 그룹에 있는 인스턴스로 트래픽을 전송합니다.
- Health check grace period:
300을 입력합니다.
- Monitoring: Enable group metrics collection within CloudWatch를 선택합니다.
기본적으로 상태 확인 유예 기간은 300으로 설정됩니다.
- Next를 선택합니다.
- Configure group size and scaling - optional 페이지에서 다음을 구성합니다.
- Desired capacity:
2를 입력합니다.
- Min desired capacity:
2를 입력합니다.
- Max desired capacity:
2를 입력합니다.
- Next를 선택합니다.
이 실습에서는 고가용성 보장을 위해 항상 2개의 인스턴스를 유지합니다. 애플리케이션이 다양한 트래픽 부하를 수신할 것으로 예상되는 경우 인스턴스를 시작 및 종료할 시기를 정의하는 조정 정책을 생성할 수도 있습니다. 하지만 이 실습의 재고 애플리케이션에는 필요하지 않습니다.
- Add tags - optional 페이지가 표시될 때까지 Next를 선택합니다.
- Add tag를 선택하고 다음을 구성합니다.
- Key:
Name을 입력합니다.
- Value - optional:
Inventory-App을 입력합니다.
그러면 Auto Scaling 그룹에 이름으로 태그가 지정되고 Auto Scaling 그룹에서 시작한 EC2 인스턴스에도 적용됩니다. 그러면 각 EC2 인스턴스와 연관된 애플리케이션이나 비즈니스 개념(예: 비용 센터)을 쉽게 식별할 수 있습니다.
- Next를 선택합니다.
- Auto Scaling 그룹 구성이 정확한지 검토한 다음, Create Auto Scaling group을 선택합니다.
곧 2개의 가용 영역에서 애플리케이션이 실행됩니다. 인스턴스 또는 가용 영역 하나에 장애가 발생하더라도 Amazon EC2 Auto Scaling은 구성을 유지합니다.
Auto Scaling 그룹을 생성했으므로 이 그룹에서 EC2 인스턴스를 시작했는지 확인할 수 있습니다.
- Inventory-ASG Auto Scaling 그룹을 선택합니다.
- Group details 섹션을 검사하여 Auto Scaling 그룹에 대한 정보를 검토합니다.
- Activity 탭을 선택합니다.
Activity history 섹션에는 Auto Scaling 그룹에서 발생한 이벤트의 레코드가 계속 표시됩니다. Status 열에는 인스턴스의 상태가 포함됩니다. 인스턴스를 시작하면 상태 열에 PreInService가 표시됩니다. 인스턴스가 시작되고 나면 상태가 Successful로 변경됩니다.
- Instance management 탭을 선택합니다.
Auto Scaling 그룹이 2개의 EC2 인스턴스를 시작했습니다. 이러한 인스턴스의 수명 주기 상태는 InService입니다. Health status 열에는 인스턴스의 EC2 인스턴스 상태 확인 결과가 표시됩니다.
새로고침: 인스턴스가 아직 InService 상태에 도달하지 않았으면 몇 분 정도 기다려야 합니다. 새로 고침 을 선택하여 인스턴스의 현재 수명 주기 상태를 검색할 수 있습니다.
- Monitoring 탭을 선택합니다. 여기에서 Autoscaling 그룹의 모니터링 관련 정보를 검토할 수 있습니다.
추가 정보: 이 페이지는 Auto Scaling 그룹에서의 활동 및 인스턴스의 사용률과 상태에 관한 정보를 제공합니다. Auto Scaling 탭에는 Auto Scaling 그룹에 대한 Amazon CloudWatch 지표가 표시되며, EC2 탭에는 Auto Scaling 그룹이 관리하는 EC2 인스턴스의 지표가 표시됩니다. 자세한 내용은, 다음을 참조하십시오. Auto Scaling 인스턴스 및 그룹 모니터링
축하합니다! 이제 애플리케이션의 가용성을 유지하고 인스턴스 또는 가용 영역 장애에 대해 복원력을 갖도록 하는 Auto Scaling 그룹을 생성했습니다. 다음으로 애플리케이션이 고가용성을 테스트합니다.
과제 4: 애플리케이션 테스트
이 과제에서는 웹 애플리케이션이 실행 중이고 가용성이 높은지 확인합니다.
- 왼쪽 상단 모서리에 있는 메뉴 아이콘 을 선택하여 탐색 메뉴를 확장합니다.
- 왼쪽 탐색 창에서 Target Groups를 선택합니다.
- Name 아래에서 Inventory-App을 선택합니다.
- 아래쪽 창에서 Targets 탭을 선택합니다.
Registered targets 섹션에 3개의 인스턴스가 있습니다. 여기에는 이름이 Inventory-App인 Auto Scaling 인스턴스 2개와 과제 1에서 검사한 AppServer라는 원래 인스턴스가 포함됩니다. Health Status 열에는 인스턴스에 대해 수행한 로드 밸런서 상태 확인 결과가 표시됩니다. 이 과제에서는 대상 그룹에서 원래 AppServer 인스턴스를 제거하고 Amazon EC2 Auto Scaling이 관리하는 2개의 인스턴스만 남깁니다.
- AppServer 인스턴스를 선택합니다.
- Deregister를 선택하여 로드 밸런서의 대상 그룹에서 인스턴스를 제거합니다.
Successfully deregistered 1 target. 메세지가 화면 상단에 표시됩니다.
인스턴스가 등록 취소되는 즉시 로드 밸런서는 대상으로의 요청 라우팅을 중지합니다. AppServer 인스턴스의 Health status 열에는 draining 상태가 표시되고, Health Status Details 열에는 진행 중인 요청이 완료될 때까지 Target deregistration is in progress가 표시됩니다. 몇 분이 지나면 AppServer 인스턴스 등록 취소가 완료되고, 등록된 대상 목록에는 2개의 Auto Scaling 인스턴스만 남습니다.
참고: 인스턴스 등록을 취소하면 로드 밸런서에서 인스턴스가 분리될 뿐입니다. AppServer 인스턴스는 사용자가 종료할 때까지 계속 무기한 실행됩니다.
- Inventory-App 인스턴스의 Health status 열에 아직 healthy가 표시되지 않으면 2개의 Inventory-App 인스턴스 모두 Health status 열에 healthy가 표시될 때까지 페이지 오른쪽 상단의 새로 고침 버튼을 사용하여 30초마다 인스턴스 목록을 업데이트하십시오. 인스턴스 초기화가 완료되려면 몇 분 정도 걸릴 수 있습니다.
상태가 끝까지 healthy로 변경되지 않을 경우 강사에게 문제 진단 지원을 요청하십시오. Health Status 열의 정보() 아이콘 위에 마우스 커서를 놓으면 상태에 대한 세부 정보가 표시됩니다.
애플리케이션을 테스트할 준비가 되었습니다. Application Load Balancer에 연결하여 애플리케이션을 테스트합니다. Application Load Balancer는 Amazon EC2 Auto Scaling이 관리하는 EC2 인스턴스 중 하나로 사용자의 요청을 전송합니다.
- 웹 브라우저의 재고 애플리케이션 탭으로 돌아갑니다.
참고: 브라우저 탭을 닫은 경우 다음 방법으로 재고 애플리케이션을 다시 열 수 있습니다.
- 왼쪽 탐색 창에서 Load Balancers를 선택합니다.
- Inventory-LB 로드 벨런서를 선택합니다.
- 창 하단에 있는 Details 탭에서 DNS 이름을 클립보드로 복사합니다.
이름은 Inventory-LB-xxxx.elb.amazonaws.com과 유사할 것입니다.
- 새 웹 브라우저 탭을 열고 클립보드에서 DNS 이름을 붙여 넣은 후 Enter 키를 누릅니다.
로드 밸런서가 EC2 인스턴스 중 하나로 사용자의 요청을 전달합니다. 인스턴스 ID와 가용 영역은 웹 페이지 하단에 표시됩니다.
- 새로고침: 웹 브라우저에서 페이지를 몇 번 새로 고칩니다. 인스턴스 ID와 가용 영역은 두 인스턴스 사이에서 변경되는 경우도 있습니다.
참고: 정보의 흐름은 다음과 같습니다.
- 퍼블릭 서브넷에 있는 Application Load Balancer로 요청을 전송합니다. 퍼블릭 서브넷은 인터넷에 연결되어 있습니다.
- Application Load Balancer가 프라이빗 서브넷에 있는 EC2 인스턴스 중 하나를 선택해 요청을 전달합니다.
- 그런 다음 EC2 인스턴스가 Application Load Balancer에 웹 페이지를 반환하고, Application Load Balancer가 웹 페이지를 웹 브라우저에 반환합니다.
다음 이미지는 이 웹 애플리케이션의 정보 흐름을 표시합니다.

과제 5: 애플리케이션 티어의 고가용성 테스트
이 과제에서는 EC2 인스턴스 중 하나를 종료하여 애플리케이션의 고가용성 구성을 테스트합니다.
- EC2 관리 콘솔로 돌아갑니다. 단, 애플리케이션 탭은 닫지 마십시오. 이후 과제에서 이 탭으로 다시 돌아옵니다.
- 왼쪽 탐색 창에서 Instances를 선택합니다.
이제 웹 애플리케이션 인스턴스 중 하나를 종료하여 장애를 시뮬레이션합니다.
- Inventory-App 인스턴스 중 하나를 선택합니다. 아무 인스턴스나 선택해도 됩니다.
- Instance State 를 선택한 다음 Terminate instance를 차례로 선택합니다.
- Terminate를 선택합니다.
잠시 후 로드 밸런서 상태 확인이 인스턴스가 응답하지 않는 것을 감지하고 들어오는 모든 요청을 나머지 인스턴스로 자동으로 라우팅합니다.
- 콘솔을 열어 두고 웹 브라우저의 Inventory Application 탭으로 전환해 페이지를 여러 번 새로 고칩니다.
페이지 하단에 표시된 가용 영역은 동일하게 유지됩니다. 인스턴스에 장애가 발생한 경우에도 애플리케이션은 계속 사용할 수 있습니다.
몇 분 후 Amazon EC2 Auto Scaling도 인스턴스 장애를 확인합니다. 2개의 인스턴스가 계속 실행되도록 Amazon EC2 Auto Scaling을 구성했기 때문에 Amazon EC2 Auto Scaling이 자동으로 대체 인스턴스를 시작합니다.
- 새로고침: EC2 관리 콘솔로 돌아갑니다. 이름이 Inventory-App인 새 EC2 인스턴스가 표시될 때까지 30초마다 새로 고침() 버튼을 사용하여 인스턴스 목록을 다시 로드합니다.
새로 시작된 인스턴스의 Status check 열 아래에는 Initializing이 표시됩니다. 몇 분 후 새 인스턴스의 상태 확인이 healthy가 되어야 하며, 로드 밸런서는 두 가용 영역 간에 트래픽 분산을 계속합니다.
- 새로고침: Inventory 애플리케이션 탭으로 돌아가 페이지를 여러 번 새로 고칩니다. 페이지를 새로 고치면 인스턴스 ID와 가용 영역이 바뀝니다.
이를 통해 애플리케이션이 현재 고가용성 상태임을 알 수 있습니다.
축하합니다! 애플리케이션 가용성이 높은 상태임을 확인했습니다.
과제 6: 데이터베이스 티어의 고가용성 구성
이전 과제에서 애플리케이션 티어의 고가용성을 확인했습니다. 하지만 Aurora 데이터베이스는 여전히 하나의 데이터베이스 인스턴스에서만 작동하고 있습니다.
과제 6.1: 여러 가용 영역에서 실행되도록 데이터베이스 구성
이 과제에서는 Aurora 데이터베이스를 여러 가용 영역에서 실행되도록 구성하여 고가용성을 제공하도록 설정합니다.
- 콘솔 상단의 검색 창에서 RDS를 검색하여 선택합니다.
- 왼쪽 탐색 창에서 Databases를 선택합니다.
- inventory-primary 값이 포함된 행을 찾습니다.
- 다섯번째 컬럼의 Region & AZ 항목의 값을 기록해둡니다. 이 값은 프라이머리 인스턴스가 배포된 가용 영역입니다.
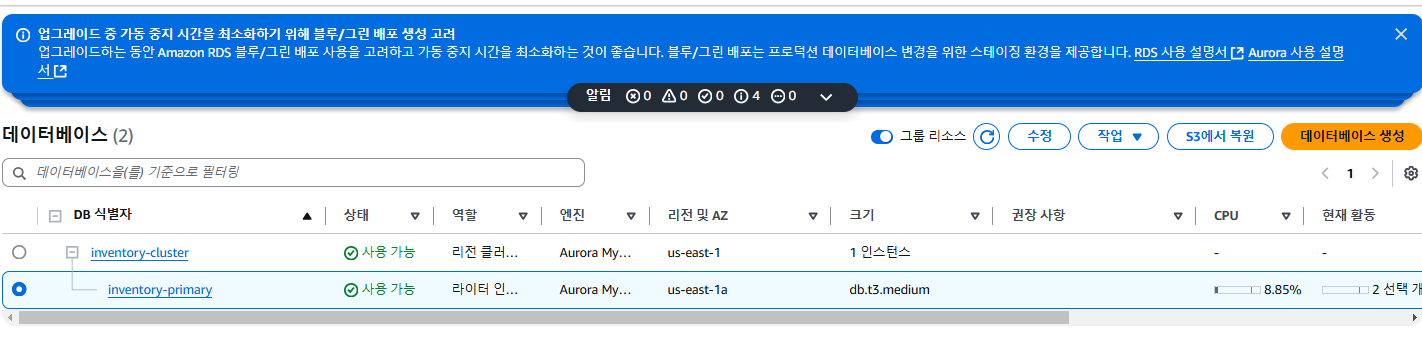
주의: 이후 단계에서 데이터베이스 클러스터를 위한 추가 인스턴스를 생성합니다. 고가용성이 실제로 보장되는 아키텍처를 구축하려면 두 번째 인스턴스는 프라이머리 인스턴스와 다른 가용 영역에 위치해야 합니다.
- Aurora 데이터베이스 클러스터와 연결된 inventory-cluster 라디오 버튼을 선택합니다.
- Actions , Add reader를 차례로 선택합니다.
- Settings 섹션에서 다음을 구성합니다.
- DB instance identifier: inventory-replica를 입력합니다.
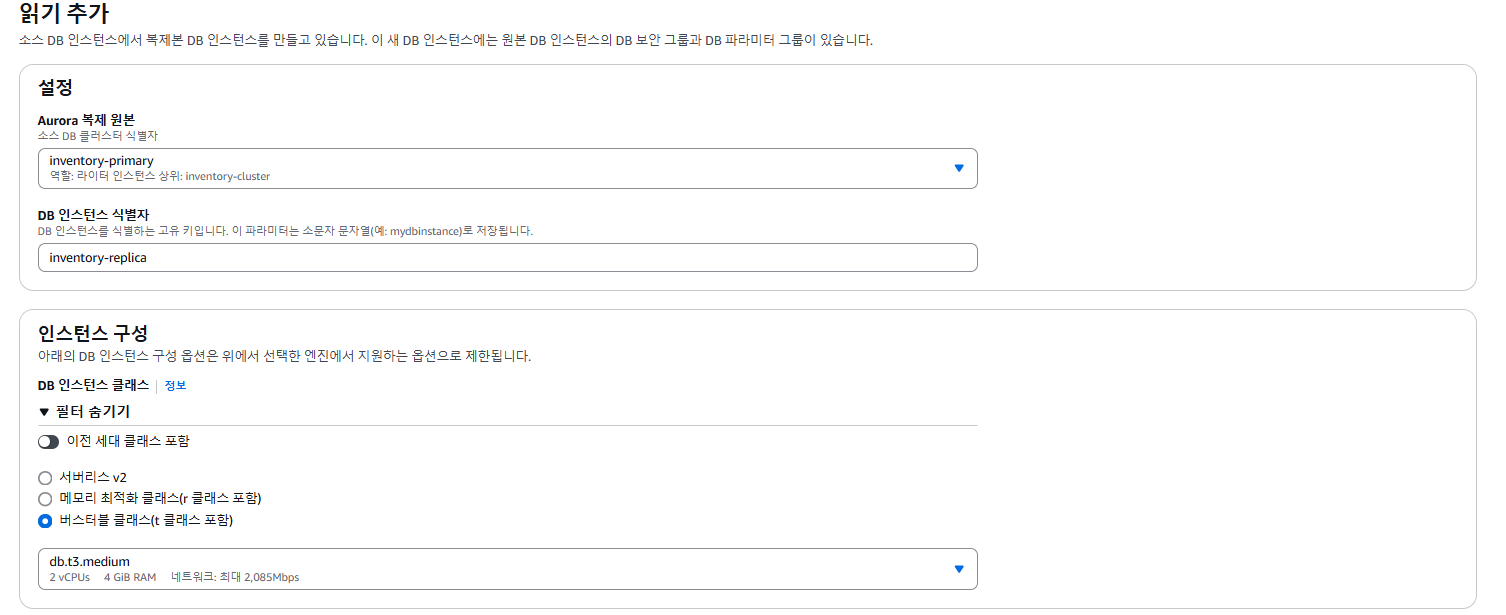
- Connectivity 섹션의 Availability Zone 아래에서 앞에서 확인한 가용 영역(inventory-primary가 있는 가용 영역)과는 다른 가용 영역을 선택합니다.
- 페이지 하단에서 Add reader를 선택합니다.
목록에 이름이 inventory-replica인 새 DB 식별자가 표시되며, 상태는 Creating입니다. 이것이 사용할 Aurora 복제본 인스턴스입니다. 기다리지 않고 다음 과제를 계속할 수 있습니다.
추가 정보: Aurora 복제본 시작이 완료되면 데이터베이스가 여러 가용 영역에 고가용성 구성으로 배포됩니다. 이는 데이터베이스가 여러 인스턴스에 분산 된다는 뜻은 아닙니다. 프라이머리 DB 인스턴스와 Aurora 복제본 모두 동일한 공유 스토리지에 액세스하지만 프라이머리 DB 인스턴스만 쓰기에 사용할 수 있습니다. Aurora 복제본의 주 용도는 두 가지입니다. Aurora 복제본에 쿼리를 실행하여 애플리케이션에 대한 읽기 작업 크기를 조정할 수 있습니다. 그러려면 일반적으로 클러스터의 Reader 엔드포인트에 연결합니다. 이렇게 하면 Aurora가 읽기 전용 연결의 부하를 클러스터에 있는 여러 Aurora 복제본에 분산시킬 수 있습니다. Aurora 복제본은 가용성을 높이는 데도 도움이 됩니다. 클러스터의 쓰기 인스턴스를 사용할 수 없게 되면 Aurora는 자동으로 읽기 인스턴스 중 하나를 새 쓰기 인스턴스로 승격합니다. 자세한 내용은, 다음을 참조하십시오. Amazon Aurora를 사용한 복제
Aurora 복제본이 시작되는 동안 다음 과제를 계속하여 NAT 게이트웨이의 고가용성을 구성하고, Amazon RDS 콘솔로 돌아와 복제본 생성 완료 후 최종 과제에서 데이터베이스의 고가용성을 확인합니다.
축하합니다! 데이터베이스 티어의 고가용성을 구성했습니다.
과제 7: NAT 게이트웨이가 고가용성을 제공하도록 설정
이 과제에서는 두 번째 가용 영역에 있는 또 다른 NAT 게이트웨이를 시작하여 NAT 게이트웨이를 고가용성으로 만듭니다.
2개의 가용 영역에 걸친 프라이빗 서브넷에 Inventory-App 서버가 배포되어 있습니다. 인터넷에 액세스해야 하는 경우(예: 데이터 다운로드) 요청은 퍼블릭 서브넷에 있는 NAT 게이트웨이를 통해 리디렉션되어야 합니다. 현재 아키텍처에는 Public Subnet 1에 NAT 게이트웨이 하나만 있고, 모든 Inventory-App 서버가 이 NAT 게이트웨이를 사용하여 인터넷에 연결합니다. 즉, 가용 영역 1에서 장애가 발생하면 어느 애플리케이션 서버도 인터넷과 통신할 수 없습니다. 가용 영역 2에 두 번째 NAT 게이트웨이를 추가하면 가용 영역 1에 장애가 발생하더라도 프라이빗 서브넷의 리소스가 인터넷에 연결할 수 있습니다.
다음 다이어그램에 표시된 그 결과 아키텍처는 가용성이 높습니다.
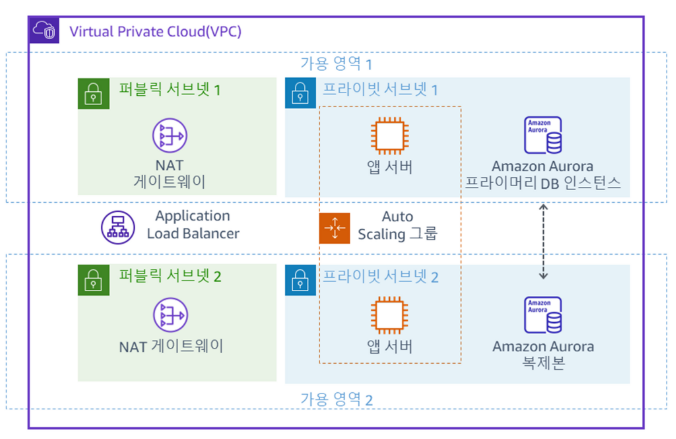
과제 7.1: 두 번째 NAT 게이트웨이 생성
- 콘솔 상단의 검색 창에서 를 검색하여 선택합니다.
- VPC
- 왼쪽 탐색 창에서 NAT gateways를 선택합니다.
기존 NAT 게이트웨이가 표시됩니다. 이제 다른 가용 영역에 NAT 게이트웨이를 생성합니다.
- Create NAT gateway를 선택하고 다음을 구성합니다.
- Name - optional:
my-nat-gateway를 입력합니다.
- Subnet: Public Subnet 2를 드롭다운 메뉴에서 선택합니다.
- Allocate Elastic IP를 선택합니다.
- Create NAT gateway를 선택합니다.

NAT gateway nat-xxxxxxxx | my-nat-gateway was created successfully. 메세지가 화면 상단에 표시됩니다.
과제 7.2: 새 라우팅 테이블 생성 및 구성
이제 트래픽을 새 NAT 게이트웨이로 리디렉션하는 새 라우팅 테이블을 Private Subnet 2에 생성합니다.
- 왼쪽 탐색 창에서 Route Tables를 선택합니다.
- Create route table을 선택하고 다음을 구성합니다.
- Name - optional:
Private Route Table 2를 입력합니다.
- VPC: 드롭다운 메뉴에서 Lab VPC를 선택합니다.
- Create route table을 선택합니다.

Route table rtb-xxxxxxx | Private Route Table 2 was created successfully. 메세지가 화면 상단에 표시됩니다.
새로 생성된 라우팅 테이블의 세부 정보가 표시됩니다. 현재는 모든 트래픽을 로컬로 보내는 경로 하나가 있습니다. 이제 새 NAT 게이트웨이를 통해 인터넷 바운드 트래픽을 보내는 경로를 추가합니다.
- Edit routes를 선택합니다.
- Add route를 선택하고 다음을 구성합니다.
- Destination:
0.0.0.0/0을 입력합니다.
- Target: NAT Gateway > my-nat-gateway를 선택합니다.
- Save changes를 선택합니다.

Updated routes for rtb-xxxxxxxxxxxx / Private Route Table 2. 메세지가 화면 상단에 표시됩니다.
라우팅 테이블을 생성하고 새 NAT 게이트웨이를 통해 인터넷 바운드 트래픽을 라우팅하도록 구성했습니다. 다음으로 라우팅 테이블을 Private Subnet 2에 연결합니다.
과제 7.3: 프라이빗 서브넷 2의 라우팅 구성
- Subnet associations 탭을 선택합니다.
- Edit subnet associations를 선택합니다.
- Private Subnet 2를 선택합니다.
- Save associations를 선택합니다.

You have successfully updated subnet associations for rtb-xxxxxxxxxxxx / Private Route Table 2. 메세지가 화면 상단에 표시됩니다.
그러면 이제 Private Subnet 2의 인터넷 바운드 트래픽을 동일한 가용 영역에 있는 NAT 게이트웨이로 보냅니다.
사용자의 NAT 게이트웨이는 이제 고가용성입니다. 한 가용 영역의 장애는 다른 가용 영역의 트래픽에 영향을 미치지 않습니다.
축하합니다! NAT 게이트웨이가 고가용성을 제공하도록 설정되었음을 확인했습니다.
과제 8: Aurora 데이터베이스 장애 조치 적용
이 과제에서는 데이터베이스가 장애 조치를 수행할 수 있는지 또는 장애 조치를 수행하는지 확인하기 위해 클러스터가 이전 작업에서 만든 Aurora 읽기 전용 복제본 인스턴스에 대한 장애 조치를 수행하도록 합니다.
- 콘솔 상단의 검색 창에서 RDS를 검색하여 선택합니다.
- 왼쪽 탐색 창에서 Databases를 선택합니다.
주의: 다음 단계를 계속 진행하기 전에 inventory-replica DB 인스턴스 상태가 Available로 변경되었는지 확인하십시오.
- DB 식별자로 Aurora 프라이머리 DB 인스턴스에 연결된 inventory-primary DB 식별자를 선택합니다.
참고: DB 식별자가 inventory-primary인 프라이머리 DB 인스턴스는 현재 Role 열 아래에는 현재 Writer가 표시됩니다. 이것은 현재 쓰기에 사용할 수 있는 클러스터의 유일한 데이터베이스 노드입니다.
- Actions를 선택합니다.
- Failover를 선택합니다.
RDS 콘솔에 Failover DB Cluster 페이지가 나타납니다.
- Failover를 선택합니다.

이제 inventory-cluster 상태는 Failing over입니다.
- 왼쪽 탐색 메뉴에서 Events를 선택합니다.
- 장애 조치가 발생하면 로그를 검토합니다. 읽기 전용 복제본 인스턴스가 종료되면 Writer로 승격된 다음, 재부팅됩니다. 읽기 전용 복제본 재부팅이 완료되면 inventory-primary가 재부팅됩니다.

장애 조치 후에도 애플리케이션이 계속 올바로 작동하는 것을 관찰합니다.
축하합니다! 데이터베이스가 장애 조치를 완료하고 고가용성을 제공하도록 설정되었음을 확인했습니다.

'아마존 클라우드' 카테고리의 다른 글
| Amazon VPC 에 Aurora 데이터베이스 계층 생성하기 (59) | 2025.03.27 |
|---|---|
| [AWS] WAF 침입 탐지 및 보호 (40) | 2025.03.26 |
| [AWS] Role Assumption Challenge (32) | 2025.03.23 |
| [AWS] Kubenetis Cluster AWS 클라우드에 구축 하기. (102) | 2024.02.28 |
| [AWS] Route53과 도메인 및 인증서 생성 (66) | 2024.02.21 |